
AI Voice Generators have exploded in popularity, providing the backbone for everything from voice assistants to Youtube narrations. Understanding the technology of AI Voice Generation is essential for anyone interested in artificial intelligence or voice technology or simply curious about how our devices talk to us.
In this guide, I’ll show you exactly how AI voice generators work. This is a companion guide to our list of the best AI Voice Generator tools you can try today.
We’ll break down the important pieces and show you some popular tools to try today, like Murf and Play.ht.
- How Do AI Voice Generators Work?
- AI in Voice Generation
- Popular AI Voice Generation Models
- Customizing Your Own AI Voice with Voice Cloning Technology
- Applications: Creating Audio and Video Content
- Understanding Voice Skins and Speech Styles
- Applications of AI Voice Generation Technology
- Challenges and Ethical Considerations
- Conclusion
How Do AI Voice Generators Work?
A modern AI voice generator is an application of a text-to-speech system and machine learning.
Text-to-Speech (TTS) systems are critical to AI voice generation technology. They convert written text into spoken words, forming the basic structure for AI voice generators.
To comprehend the workings of TTS systems, it’s crucial to understand their three primary components:
Text Preprocessing
Phonetic Analysis
Speech Synthesis
Text Preprocessing
Text preprocessing is the first phase in the TTS pipeline. The raw text is converted into a suitable format for subsequent processing in this stage. This includes several key steps:
Tokenization: This is the process of breaking down the text into individual words or “tokens”. For example, the sentence “AI is fascinating” would be tokenized into “AI”, “is”, “fascinating”.
Normalization: During normalization, any irregularities in the text are addressed. This could involve expanding contractions (e.g., “it’s” becomes “it is”), converting numbers to words (e.g., “100” becomes “one hundred”), and handling special characters or symbols.
Part of Speech Tagging: In this step, each word in the text is labeled with its corresponding part of speech (e.g., noun, verb, adjective). This helps the TTS system understand the context and usage of each word.

Phonetic Analysis
Once the text has been preprocessed, it moves into the phonetic analysis phase. Here, the preprocessed text is converted into a phonetic transcription. This transcription represents how each word in the text should be pronounced.
Phonetic analysis is crucial for generating accurate and natural-sounding speech. It considers factors like stress, intonation, and rhythm, which play a significant role in how we perceive speech.
Speech Synthesis
The final phase in the TTS process is speech synthesis, where the phonetic transcriptions are converted into actual speech. This involves generating the sound waves that correspond to the phonetic symbols.
Traditionally, this was done using concatenative synthesis or formant synthesis, which involved stitching together pre-recorded clips of speech or using mathematical models to generate speech, respectively.
However, modern TTS systems use sophisticated AI models to perform speech synthesis. These models generate speech by predicting the audio waveform directly, leading to more natural and expressive speech output.
Understanding these components – text preprocessing, phonetic analysis, and speech synthesis – is fundamental to grasping the workings of TTS systems and, by extension, AI voice generators.

AI in Voice Generation
Artificial Intelligence plays a pivotal role in modern voice generation. Over the years, AI has brought major advancements to the field, significantly improving the naturalness and intelligibility of synthetic speech.
AI in Voice Generation works by training models on large datasets of human voices. The models learn to mimic the characteristics of human speech, including pitch, intonation, speed, and emotion, resulting in a more human-like output. This is a significant departure from traditional TTS systems, which relied on pre-recorded clips of human speech or mathematical models to generate more human-like speech.
Popular AI Voice Generation Models
Several AI models have risen to prominence in the field of voice generation. Murf, Play.ht, Tacotron, and WaveNet stand out for their sophisticated speech technology and high-quality output.
Murf.ai
Murf is a customizable AI voice-over platform that provides various AI voices. It allows users to adjust the voice parameters like speed, pitch, and emotions to create more lifelike voices.
Play.ht
Play.ht offers many realistic voices to play with – over 600! Its API lets you integrate real-time voice synthesis in seconds. Plus, it has some other customer-friendly features, such as letting you convert blog posts to AI voices.
Tacotron
Tacotron is a model developed by Google that uses a sequence-to-sequence framework for TTS. It takes characters as input and produces a spectrogram (a visual representation of the spectrum of frequencies in sound), which is then converted into speech.

WaveNet
WaveNet, a Google product, uses a deep learning model to directly generate a raw audio waveform, creating more natural-sounding speech than older methods. It can generate voices in multiple languages and even produce music.
Customizing Your Own AI Voice with Voice Cloning Technology
Voice cloning technology is an exciting advancement in AI voice generation. It opens up a world of possibilities, allowing users to create a unique, personalized voice that can be used to communicate digitally.
This technology leverages advanced AI voice generator tools to analyze the nuances of a person’s speech patterns and generate a voice that resembles their own. This process of creating an AI-generated voice requires the use of neural networks and vast quantities of data to mimic human speech accurately.
Best AI Voice Generator for Cloning Your Own Voice
Several online text-to-speech voice generating software tools allow you to clone your own voice. Here are a few of the best AI voice cloning tools you can use to generate voices that sound lifelike:
Murf AI: Murf offers a voice cloning feature and a wide range of pre-generated voices. The cloned voices are of high quality and offer a realistic voice experience.
Resemble AI: This tool provides a platform to clone your voice using just a few minutes of audio samples. The synthetic voices created are incredibly lifelike, making it a popular choice for generating personalized AI voices.
Lyrebird AI: Now part of Descript, Lyrebird AI offers impressive voice cloning capabilities. With just a minute of recorded speech, Lyrebird can generate a unique AI voice that sounds like you.
Many of these cloning tools can also be found on our list of best AI voice generators. They offer a free version so you can sample things before you purchase.
By using voice cloning technology, individuals can bring a more personal touch to their voice recordings and digital interactions, creating their own AI voice.
Applications: Creating Audio and Video Content
The AI voice generator tool has revolutionized how we create and consume content. Thanks to the advancements in AI voice technology, generating audio files or voiceovers for video content is now easier than ever before.
For instance, podcasters can use AI voice generators to create high-quality, realistic voice narrations for their episodes. They can choose from a wide range of different voices or even use their own AI voice to make their podcast more personal.

Similarly, video creators can leverage AI voice generators to produce voiceovers for their content. The ability to customize the voice’s speed, tone, and emphasis allows for a more engaging and dynamic video experience.
Furthermore, AI voice generators are making significant inroads into e-learning. Educators and content creators can use these tools to develop comprehensive and accessible online tools and learning materials. From narrating entire courses to providing audio explanations of complex concepts, AI voice generators are powerful tools in digital education.
Understanding Voice Skins and Speech Styles
Voice skins and speech styles are innovative features of modern AI voice generators that allow users to add a unique touch to the generated voice.
A voice skin is a filter applied to the generated voice, altering its characteristics to sound like a different person or persona. Whether you want your text read in the style of a famous celebrity or a beloved cartoon character, voice skins make it possible.
On the other hand, speech styles refer to the way the AI voice delivers the text. Users can adjust aspects like emphasis, pitch, speed, and intonation to further create speech with a specific mood or tone.
Want to make an important point stand out? Add emphasis. Need to convey a cheerful message? Increase the pitch and speed.
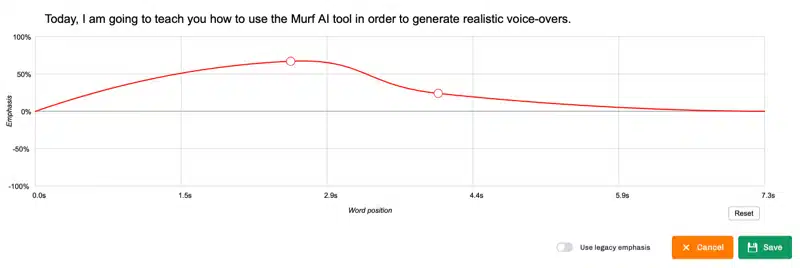
By understanding and using voice skins and speech styles, users can make the most out of their AI voice generator, creating audio content that is engaging, dynamic, and tailored to their specific needs.

Applications of AI Voice Generation Technology
AI voice generation is used in various applications, from voice assistants like Siri and Alexa, to navigation systems, customer service bots, and even in the entertainment industry for creating character voices in video games or movies.
Voice assistants use AI voice generation to interact with users more naturally and intuitively. The speech is not pre-recorded but generated on the fly based on the user’s queries.
In the entertainment industry, AI voice generation is used to create character voices, videos, narrate stories, or provide commentary. It allows for creating a wide range of voices without the need for a human voice actor.
Moreover, AI voice generation plays a significant role in accessibility technology. It enables text-to-speech functionality for visually impaired users or those with reading difficulties, enhancing their digital experiences and ensuring equal access to information.
With the future of AI voice generation looking bright, these applications are just the tip of the iceberg. As the technology improves, we can expect to see even more innovative uses of AI voice generation.
Challenges and Ethical Considerations
Despite the advancements and potential, AI voice generation has challenges and ethical considerations.
One of the primary technical challenges is achieving high-quality, natural-sounding speech. While we’ve made significant strides, there’s still a gap between AI-generated speech and actual human speech, particularly when expressing emotions or handling complex sentences.
Ethically, the use of AI-generated voices raises several concerns. There’s the risk of misuse in ldeepfakes, where AI-generated voices could be used to impersonate individuals.
Privacy is another concern, as training these models requires massive amounts of data, potentially including sensitive personal information.
Conclusion
Understanding the technology behind AI voice generators is crucial as we increasingly rely on these tools in our daily lives.
From the fundamental workings of Text-to-Speech systems to the role of AI in voice generation and the different models like Tacotron, WaveNet, and Murf, each aspect contributes to the evolution and potential of this technology.
The importance of AI voice generation cannot be overstated both in terms of current applications and future possibilities. However, it’s equally important to recognize and address this technology’s challenges and ethical considerations.
As we look towards the future of AI voice generation, embracing this balance will be key to leveraging this technology for the greatest benefit.